

Selecting the Right Feature Engineering Strategy: A Decision Tree Approach.
Image by Author | Ideogram
In machine learning model development, feature engineering plays a crucial role since real-world data often comes with noise, missing values, skewed distributions, and even inconsistent formats. Accordingly, feature engineering encompasses a wide range of techniques to transform, enrich, or simplify raw features into a better and more consistent form before model training or analysis.
To help you identify the right feature engineering approaches to apply to your dataset’s features, this article provides a decision tree-based guide that navigates you toward the most suitable strategies, depending on the nuances and types of data involved.
A Decision Tree Guide to Selecting the Right Feature Engineering Strategies
This decision tree has been designed as the central visual aid for helping you select which feature engineering strategies to apply to your dataset before proceeding to build machine learning models or conduct other advanced data analysis tasks.
Why “strategies” (plural)? Your dataset may typically contain several features, various of which might require their own feature engineering strategies to be applied. Would we still need to apply several strategies (again, in plural) rather than a single one to a specific attribute? Well, sometimes.
For instance, if a numerical attribute is skewed and also used in a distance-based model, you may want to standardize your attribute values into z-scores — see diagram above — and also use it alongside another numerical attribute to apply multiplicative interactions, yielding a new, more informative feature. Not to mention, you may also want to add an extra attribute to “label” instances containing outliers, as described later on.
Let’s look into and demystify some of the techniques and data characteristics mentioned throughout the tree, so you can gain a better understanding of when and why to use them.
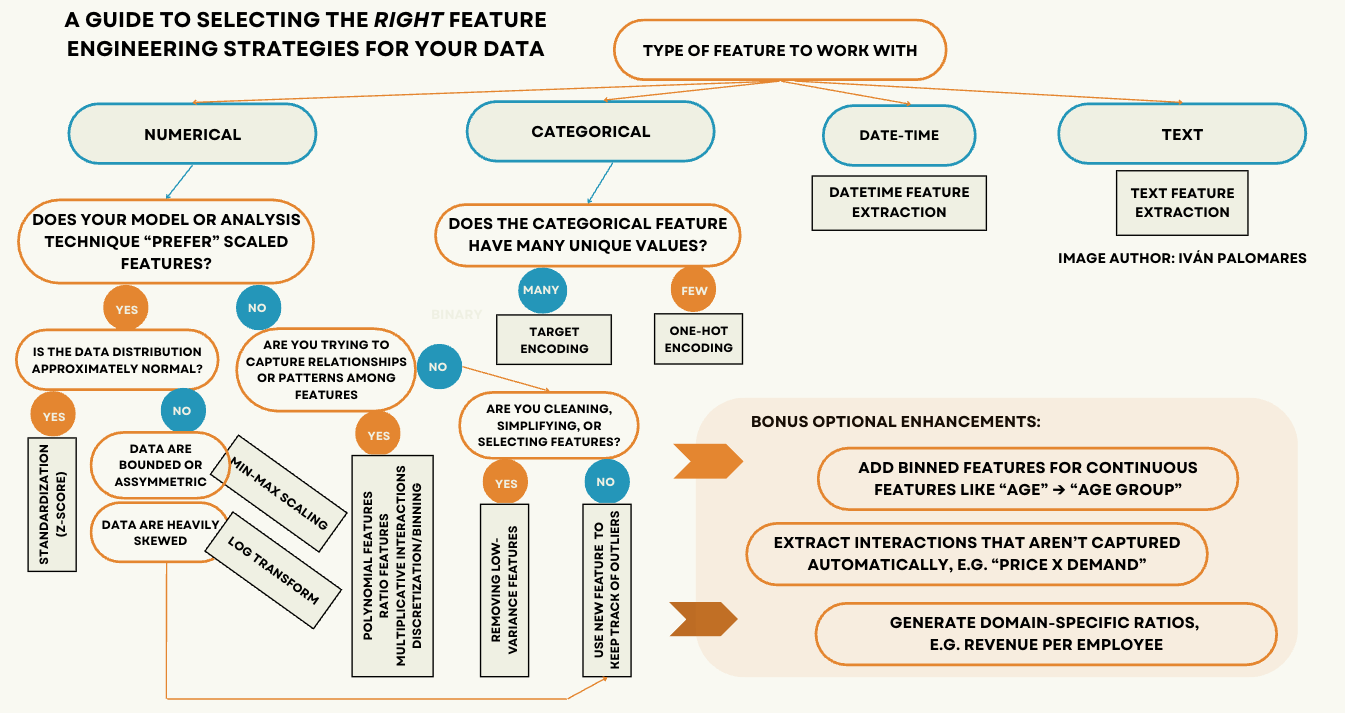
Selecting the Right Feature Engineering Techniques (click to enlarge)
Image by Author
Numerical Features
First, many machine learning algorithms require numerical data to be scaled properly, since differences in feature ranges can negatively affect model performance. For example, features with large ranges, like house prices, may dominate others when using models that rely on distance metrics or gradient descent optimization. Thankfully, popular Python libraries like scikit-learn provide implementations to handle these processes seamlessly.
Common types of feature scaling include standardization (z-scores), which is useful when the data is approximately normally distributed and when there are no extreme outliers. Meanwhile, min-max scaling, which normalizes values within a feature to the unit interval [0, 1], is suitable when preserving the relative relationships and original values distribution is key. Lastly, if your feature distribution is heavily skewed, a logarithmic (log) transformation can help “compress” unduly large values and bring the distribution closer to normal.
One of the most common goals of feature engineering is to capture relationships or patterns among two or more existing features, creating new ones that reflect such interactions. Methods like polynomial feature extraction, calculating ratios, applying multiplicative interactions, or discretizing high-granularity continuous features can improve model performance by making these latent relationships more explicit. These techniques can help non-interaction-aware models (like linear regression) capture nonlinearities while keeping a good level of model interpretability.
In addition to the strategies already discussed, we may also want to simplify our feature set by removing those with very low variance: such features typically provide little or no useful information to the model to perform inference. Furthermore, while outliers can sometimes be informative, it can be useful to create a new boolean feature to keep track of them, enabling your model or analysis to distinguish between typical and atypical observations.
Non-Numerical Features: Categorical, Date-Time, and Text
How about non-numerical features? While a vast majority of machine learning algorithms and models are designed to handle mostly numerical information, there are ways to encode other types of data, often in a numerical format that these models can digest.
Categorical features usually take a small number of possible values (categories). For instance, a textile product may have one out of four possible colors to choose from. In these situations, one-hot encoding, which creates several binary columns — one for each category — is the most common approach. On the contrary, for categorical attributes with many possible values, such as the state or province a person belongs to across an entire country, target encoding is a more effective strategy. This involves replacing each category with the average value of the target variable for that category, allowing the model to retain useful information without inflating the feature space. This strategy should be used with caution to avoid possible data leakage.
Date-time feature extraction is a frequently needed task to obtain structured variables like the hour of the day, day of the month, or whether a date falls on a weekday, weekend, or holiday. These features can disclose phenomena in time series data like seasonality, trends, or behavioral patterns relevant to predictive analysis and modeling.
Text feature extraction is useful for machine learning models dealing with unstructured text. This is typically done by converting text into numerical representations, including word counts, term frequency-inverse document frequency (TF-IDF), or word embeddings, enabling models to comprehend and leverage textual data effectively.
Wrapping Up
This article provided a decision tree-oriented guide to choose the right feature engineering techniques and strategies to apply to diverse datasets and features before moving on to further analysis processes and machine learning modeling. Feature engineering is more often than not the key to turn raw data into valuable inputs for these models to make the most of them and do their intended task at their best.