

In this article, you will learn a practical, production-focused framework for testing and measuring the real-world performance of agentic AI systems.
Topics we will cover include:
- Why evaluating agents differs fundamentally from evaluating standalone language models.
- The four pillars of agent evaluation and the most useful metrics for each.
- How to build an automated, human, or hybrid evaluation pipeline that catches failures early.
Let’s get right to it.
Agent Evaluation: How to Test and Measure Agentic AI Performance (click to enlarge)
Image by Author
{kind=link}
Introduction
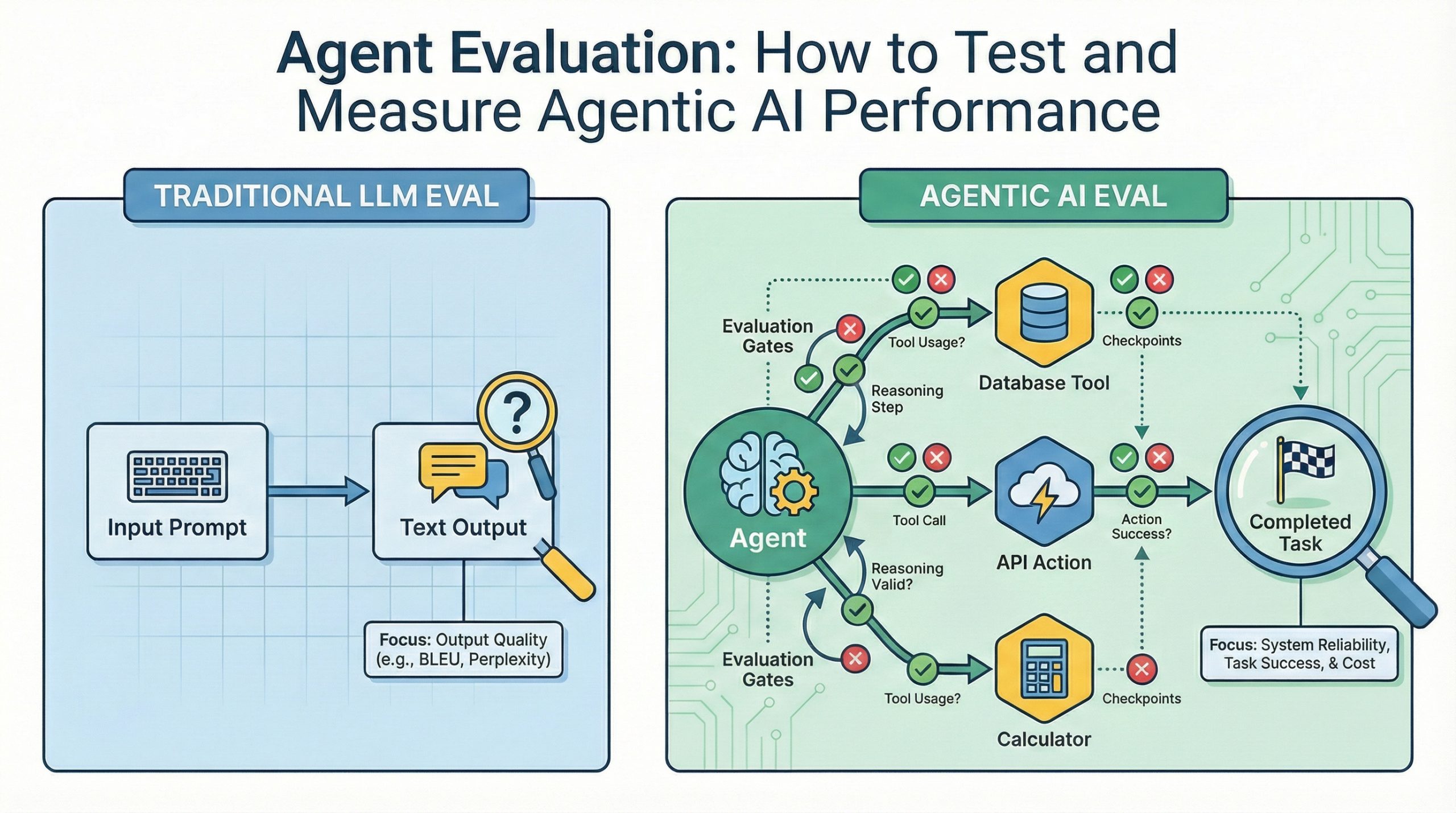
AI agents that use tools, make decisions, and complete multi-step tasks aren’t prototypes anymore. The challenge is figuring out whether your agent actually works reliably in production. Traditional language model evaluation metrics like BLEU scores or perplexity miss what matters for agents. Did it accomplish the task correctly? Did it use tools appropriately? Could it recover from failures?
This guide covers a practical framework for evaluating agent performance across four dimensions that determine production readiness. You’ll see what to measure, which evaluation methods fit different use cases, and how to build an evaluation pipeline that catches problems before they hit users.
Why Agent Evaluation Differs from LLM Evaluation
Evaluating standalone language models focuses on text quality metrics like coherence, factual accuracy, and response relevance. These metrics assume the model’s job ends when it generates text. Agent evaluation requires a different approach because agents don’t just generate text. They take actions, invoke tools with specific parameters, make sequential decisions that build on previous steps, and must recover when external APIs fail or return unexpected data.
A customer support agent needs to look up order status, process refunds, and update customer records. Traditional LLM metrics tell you nothing about whether it called the right API endpoints, passed correct customer IDs, or handled cases where refund requests exceeded policy limits. Agent evaluation must assess task completion success, tool invocation accuracy, reasoning quality across multi-step workflows, and failure handling.
Evaluating language models versus evaluating agents is like testing a calculator’s display versus testing an entire financial system. One focuses on output quality, the other on whether the system accomplishes its intended purpose reliably under real conditions.
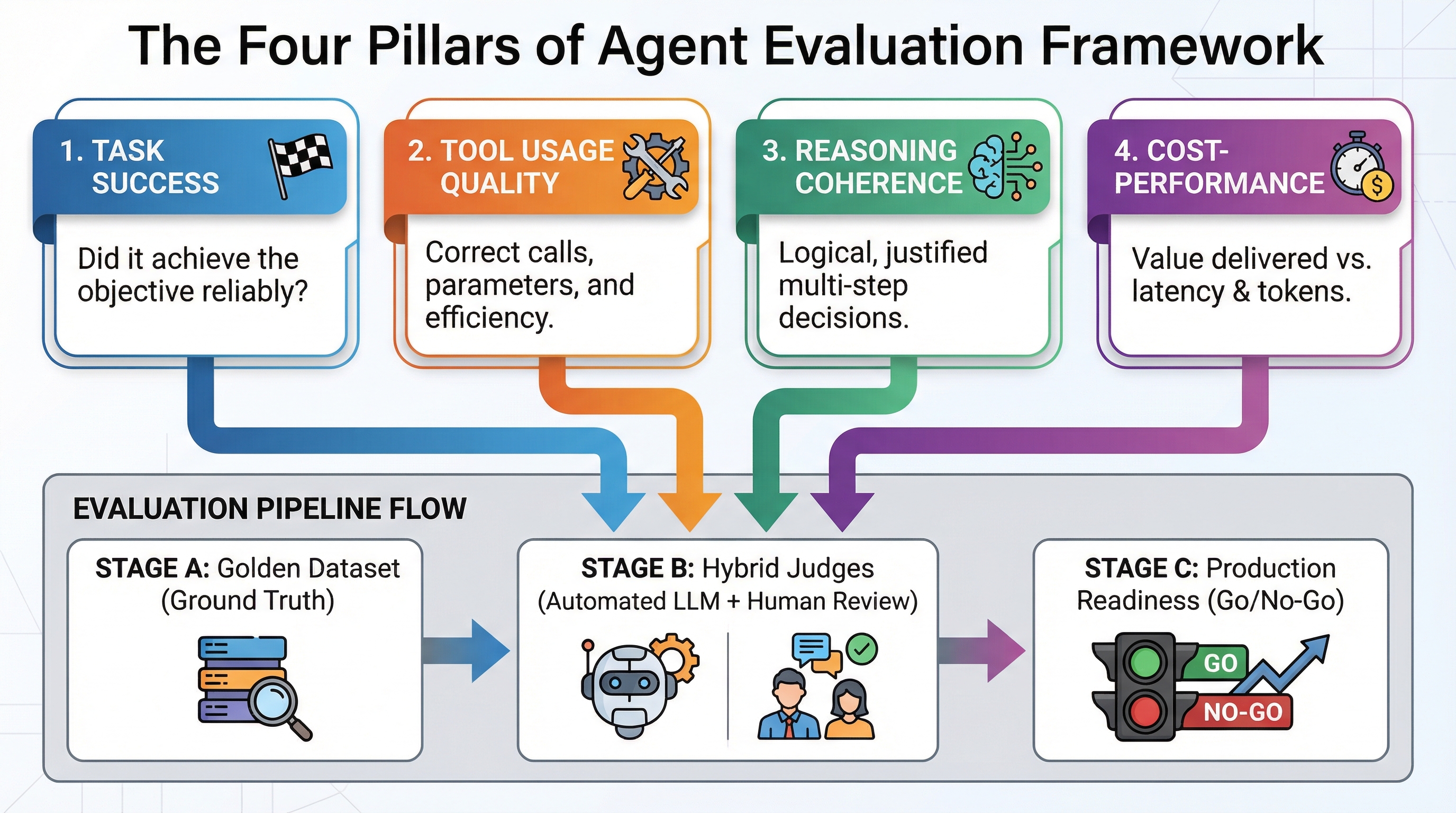
The Four Pillars of Agent Evaluation
Agent evaluation frameworks measure four interconnected dimensions. Each addresses a different failure mode that can break agent reliability.
Task Success measures whether the agent accomplished its assigned objective. This requires precise definition. For a customer support agent, “resolved the customer inquiry” might mean the customer’s question was answered (outcome-based), that all required workflow steps were completed (process-based), or that the customer expressed satisfaction (quality-based). Different definitions lead to different evaluation approaches and optimization strategies.
Tool Usage Quality examines whether the agent invoked the right tools with correct arguments at appropriate times. Poor tool usage appears in several forms: calling tools that don’t help achieve the goal (relevance failures), passing malformed parameters that cause API errors (accuracy failures), making redundant calls that waste tokens and latency (efficiency failures), or skipping necessary tool calls (completeness failures). Reliable tool calling patterns distinguish production agents from prototype demonstrations.
Reasoning Coherence assesses whether the agent’s decision-making process was logical and justified given available information. Production systems need interpretability and debugging capability. An agent that arrives at the right solution through illogical reasoning will fail unpredictably as conditions change. Reasoning evaluation examines whether intermediate steps follow from previous observations, whether the agent considered relevant alternatives, and whether it updated beliefs appropriately when new information contradicted assumptions.
Cost-Performance Trade-offs quantify what each successful task costs in tokens, API calls, latency, and infrastructure resources relative to the value delivered. An agent that achieves 95% task success but requires 50 API calls and 30 seconds per task may be technically correct but economically unviable. Evaluation must balance accuracy against operational costs to find architectures that deliver acceptable performance at sustainable expense.
This evaluation rubric provides concrete measurement dimensions:
| Pillar | What You’re Measuring | How to Measure | Example Metric |
|---|---|---|---|
| Task Success | Did the agent complete the objective? | Binary outcome plus quality scoring | Task completion rate (0-100%) |
| Tool Usage Quality | Did it call the right tools with correct arguments? | Deterministic validation plus LLM-as-a-Judge | Tool call accuracy, parameter correctness |
| Reasoning Coherence | Were intermediate steps logical and justified? | LLM-as-a-Judge with chain-of-thought analysis | Reasoning quality score (1-5 scale) |
| Cost-Performance | What did it cost versus value delivered? | Token tracking, API monitoring, latency measurement | Cost per successful task, time to completion |
Pick one or two metrics from each pillar based on your production constraints and failure modes you need to catch. You don’t need to measure everything, just what matters for your specific use case.
Three Evaluation Approaches: Automated, Human, and Hybrid
Agent evaluation implementations fall into three categories based on who or what performs the evaluation.
LLM-as-a-Judge uses a more capable model to evaluate your agent’s outputs automatically. GPT-4 or Claude assesses whether your agent’s responses met quality criteria that are difficult to specify as deterministic rules. The evaluator model receives the agent’s input, its output, and a grading rubric, then scores the response on dimensions like helpfulness, accuracy, or policy compliance. This handles subjective criteria that resist simple validation rules, such as tone appropriateness or explanation clarity, while maintaining the speed and consistency of automated testing.
LLM-as-a-Judge evaluation works best when you can provide clear evaluation criteria in the prompt and when the evaluator model has sufficient capability to assess the dimensions you care about. Watch for evaluator models that are too lenient (grade inflation), too strict (false failures), or inconsistent across similar cases (unstable scoring).
Human evaluation involves actual people reviewing agent outputs against quality criteria. This catches edge cases and subjective quality issues that automated methods miss, especially for tasks requiring domain expertise, cultural awareness, or nuanced judgment. The main challenges are cost, speed, and scaling. Human evaluation costs $10-50 per task depending on complexity and reviewer expertise, takes hours to days rather than seconds, and can’t continuously monitor production traffic. Human evaluation works best for calibration datasets, failure analysis, and periodic quality audits rather than continuous monitoring.
Hybrid approaches combine automated filtering with human review of important cases. Start with LLM-as-a-Judge for first-pass evaluation of all agent outputs, then route failures, edge cases, and high-stakes decisions to human reviewers. This provides automation’s speed and coverage while maintaining human oversight where it matters most. The approach mirrors evaluation strategies used in RAG systems, where automated metrics catch obvious failures while human review validates retrieval relevance and answer quality.
Evaluation method choice depends on your specific constraints. High-volume, low-stakes tasks favor pure automation. High-stakes decisions with complex quality criteria need human review. Most production systems benefit from hybrid approaches that balance automation with targeted human oversight.
Agent-Specific Benchmarks and Evaluation Tools
The agent evaluation ecosystem includes specialized benchmarks designed to test capabilities beyond simple text generation. AgentBench provides multi-domain testing across web navigation, database querying, and knowledge retrieval tasks. WebArena focuses on web-based agents that must navigate sites, fill forms, and complete multi-page workflows. GAIA tests general intelligence through tasks requiring multi-step reasoning and tool use. ToolBench evaluates tool usage accuracy across thousands of real-world API scenarios.
These benchmarks establish baseline performance expectations. Knowing that current best agents achieve 45% success on GAIA’s hardest tasks helps you calibrate whether your 35% success rate represents a problem requiring architecture changes or simply reflects task difficulty. Benchmarks also enable direct comparisons when evaluating different agent frameworks or base models for your use case.
Implementation tools have emerged to make evaluation work in production systems. LangSmith provides built-in agent tracing that visualizes tool calls, intermediate reasoning steps, and decision points, with integrated evaluation pipelines that run automatically on every agent execution. Langfuse offers open-source observability with custom evaluation metric support, letting you define domain-specific graders beyond standard benchmarks. Frameworks originally built for RAG evaluation, like RAGAS, are being extended to support agent-specific metrics such as tool call accuracy and multi-step reasoning coherence.
You don’t need to build evaluation infrastructure from scratch. Choose tools based on whether you need hosted solutions with quick setup (LangSmith), full customization (Langfuse), or integration with existing RAG pipelines (RAGAS extensions). The evaluation method matters more than the specific tool, as long as your chosen platform supports the automated, human, or hybrid approach your use case requires.
Building Your Agent Evaluation Pipeline
Effective evaluation pipelines start with a foundation that many teams skip: the golden dataset. This curated collection of 20-50 examples shows ideal inputs and expected outputs for your agent. Each example specifies the task, the correct solution, the tools that should be invoked, and the reasoning that should occur. You need this ground truth reference to measure against.
Creating a golden dataset requires actual engineering work. Review your production logs to find representative tasks across difficulty levels. For each task, manually verify the correct solution and document why alternative approaches would fail. Include edge cases that broke your agent during testing. Update the dataset as you discover new failure modes. This preparatory work determines everything that follows.
Define clear success criteria aligned with your four pillars. For task success, specify whether partial completion counts or only full resolution matters. For tool usage, decide if calling redundant tools that don’t hurt the outcome constitutes failure. For reasoning, establish whether you care about elegant solutions or just correct ones. For cost-performance, set hard limits on acceptable latency and token usage. Vague criteria lead to evaluation systems that catch nothing useful.
Select three to five core metrics that span your four pillars. Task completion rate covers task success. Tool call accuracy addresses usage quality. An LLM-as-a-Judge reasoning score handles coherence. Average tokens per task quantifies cost. These four metrics provide solid coverage without overwhelming your monitoring dashboards.
Implement automated LLM-as-a-Judge evaluation that runs on every deployment before production. This catches obvious regressions like tool calls with swapped parameters or reasoning that contradicts the task objective. Automated evaluation should block deployments that fail your core metrics by more than threshold amounts, typically 5-10% drops in success rate or 20-30% increases in cost per task.
Establish human review processes for failures and edge cases. When automated evaluation flags a failure, route it to domain experts who can determine whether the evaluation was correct or revealed an evaluation bug. When agents encounter situations not covered in your golden dataset, have humans assess the response quality and add validated examples to expand your ground truth. This iterative improvement cycle mirrors best practices from RAG systems, where continuous evaluation and dataset expansion drive reliability improvements.
Start simple and add sophistication as you understand your failure patterns. Begin with task success rates on your golden dataset. After you reliably measure completion, add tool usage metrics. Then introduce reasoning evaluation. Finally, optimize cost-performance once quality metrics stabilize. Attempting full evaluation from day one creates complexity that obscures whether your agent actually works.
Common Evaluation Pitfalls and How to Avoid Them
Three failure modes consistently derail agent evaluation efforts. First, teams evaluate on synthetic data that doesn’t reflect production complexity. Agents that ace clean test cases often fail when real users provide ambiguous instructions, reference previous context, or combine multiple requests. Solve this by seeding your golden dataset with actual production failures rather than idealized scenarios.
Second, evaluation criteria drift from business objectives. Teams optimize for metrics like API call reduction or reasoning elegance that don’t map to what actually matters: did the customer’s problem get solved? Regularly validate that your evaluation metrics predict real-world success by comparing agent scores against actual user satisfaction data or business outcomes.
Third, evaluation systems fail to catch regressions because test coverage doesn’t span the agent’s capability space. An agent might excel at data retrieval tasks while silently breaking on calculation tasks, but limited test examples only exercise the retrieval path. Test design requires examples covering each design pattern your agent implements and each tool in its repertoire.
These pitfalls share a common root: treating evaluation as a one-time setup task rather than an ongoing practice. Reliable evaluation requires continuous investment in test case quality, metric validation, and coverage expansion as your agent’s capabilities grow.
Conclusion
Reliable agent evaluation requires measuring task success, tool usage quality, reasoning coherence, and cost-performance trade-offs through a combination of automated LLM-as-a-Judge assessment, deterministic validation, and targeted human review. The foundation is a golden dataset of 20-50 curated examples that define what success looks like for your specific use case.
Start with simple task completion metrics on real production scenarios. Add sophistication only after you understand your failure modes. Choose evaluation tools based on whether you need hosted convenience or full customization, but recognize that your evaluation approach matters more than the specific platform.
For implementation details on building production evaluation pipelines, check out Anthropic’s “Demystifying evals for AI agents”, which provides an eight-step technical roadmap with grader schemas, YAML configurations, and real customer case studies showing how teams like Descript and Bolt evolved their evaluation approaches.