


Image by Author
After the highly successful launch of Gemma 1, the Google team introduced an even more advanced model series called Gemma 2. This new family of Large Language Models (LLMs) includes models with 9 billion (9B) and 27 billion (27B) parameters. Gemma 2 offers higher performance and greater inference efficiency than its predecessor, with significant safety advancements built in. Both models outperform the Llama 3 and Gork 1 models.
In this tutorial, we will learn about the three applications that will help you run the Gemma 2 model locally faster than online. To experience the state-of-the-art model locally, you just have to install the application, download the model, and start using it. It is that simple.
1. Jan
Download and install Jan from the official website. Jan is my favorite application for running and testing various open-source and property LLMs. It is super easy to set up and highly flexible in terms of importing and using local models.
Launch the Jan application and go to the Model Hub menu. Then, paste the following link of the Hugging Face repository into the search bar and press enter: bartowski/gemma-2-9b-it-GGUF.
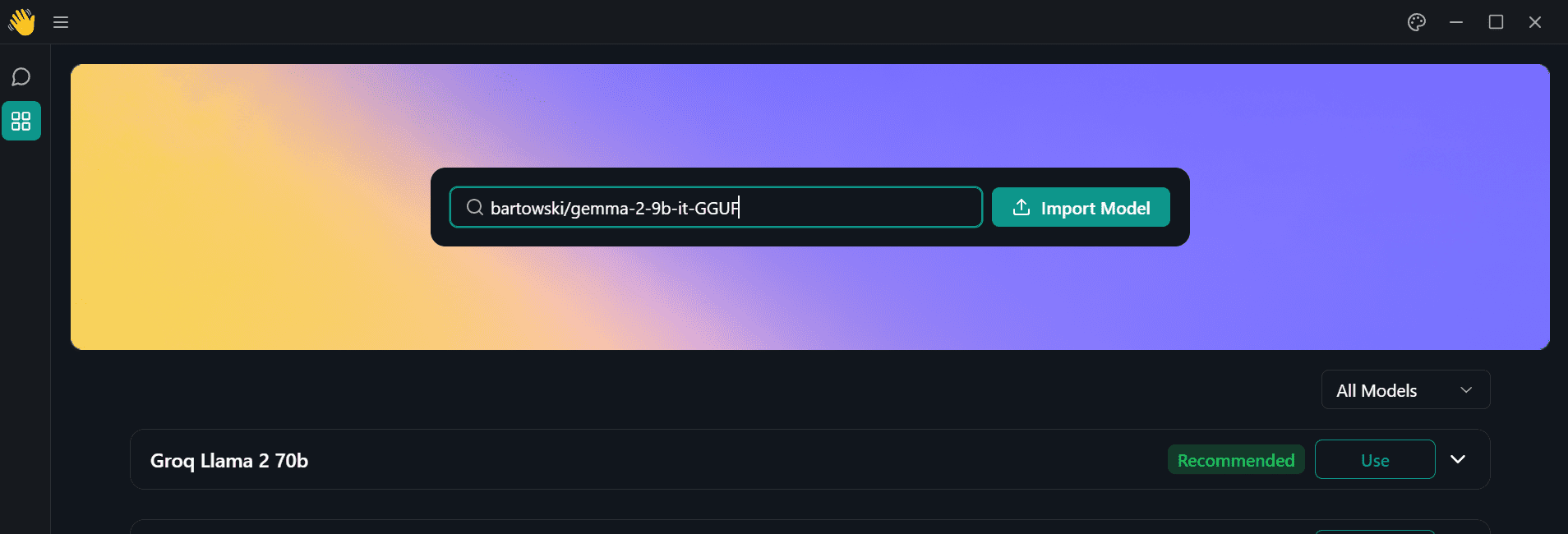
Image by Author
You will be redirected to a new window, where you have the option to select various quantized versions of the model. We will be downloading the “Q4-K-M” version.
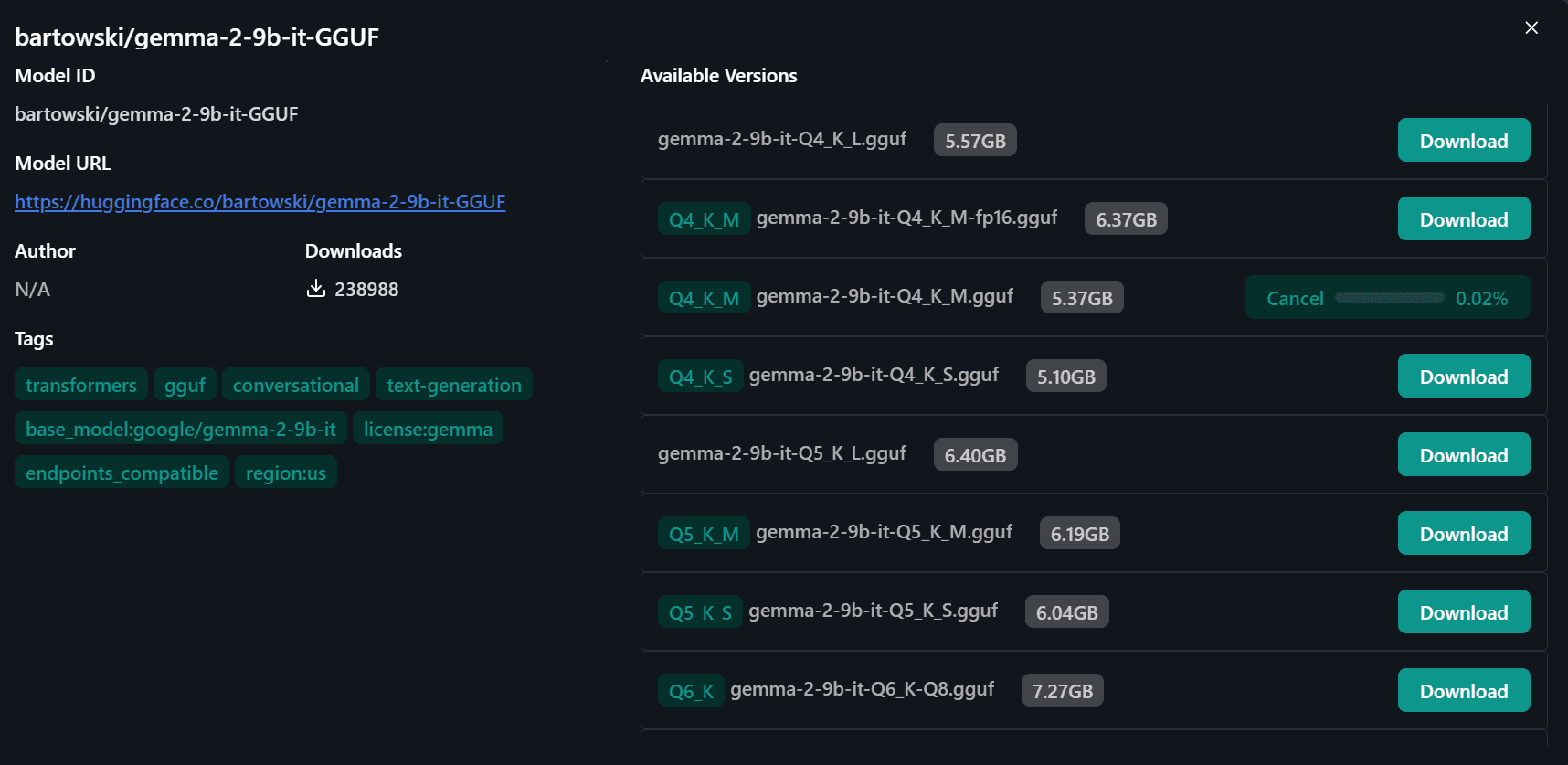
Image by Author
Select the downloaded model from the model menu on the right panel and start using it.
This version of the quantized model currently gives me 37 tokens per second, but you might improve your speed even further if you use a different version.
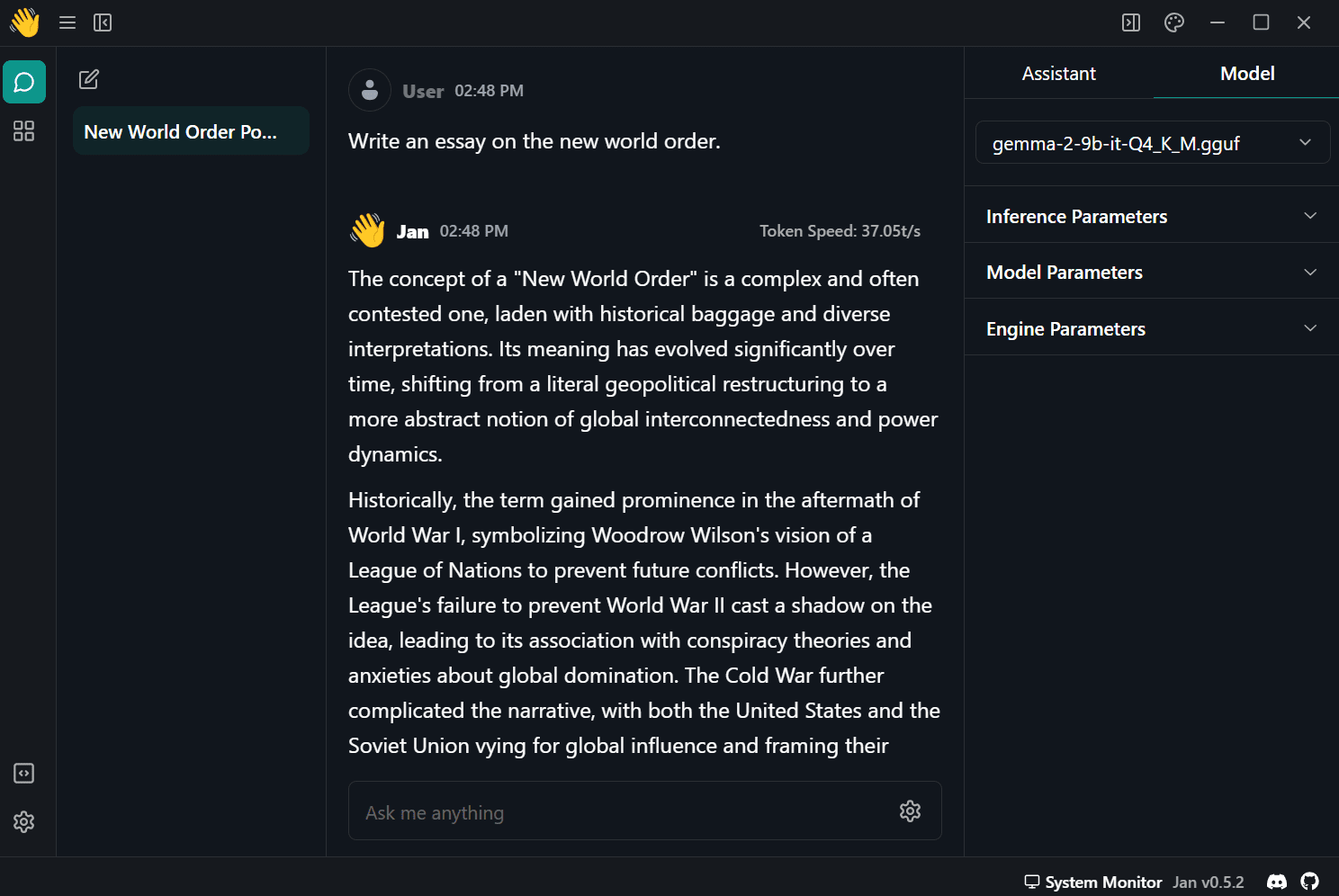
Image by Author
2. Ollama
Go to the official website to download and install Ollama. It is a favorite among developers and people who are familiar with terminals and CLI tools. Even for new users, it is simple to set up.
After installation is completed, please launch the Ollama application and type the following command in your favorite terminal. I am using Powershell on Windows 11.
Depending on your internet speed, it will take approximately half an hour to download the model.
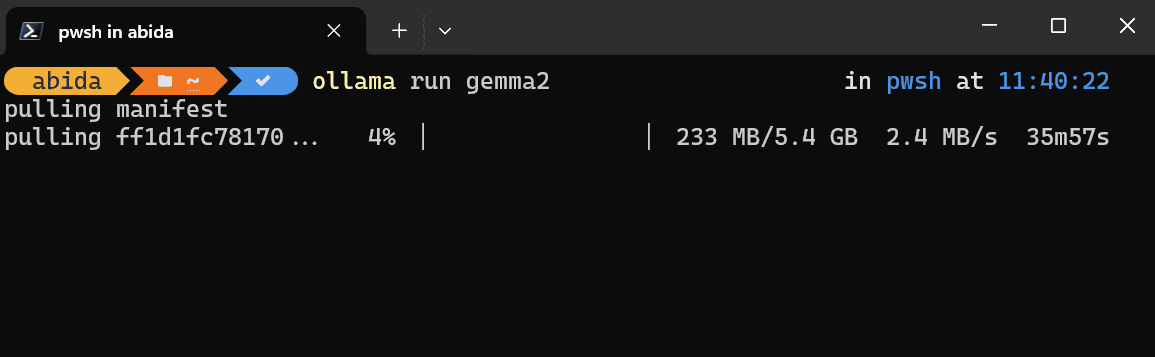
Image by Author
After the download is complete, you can start prompting and start using it within your terminal.
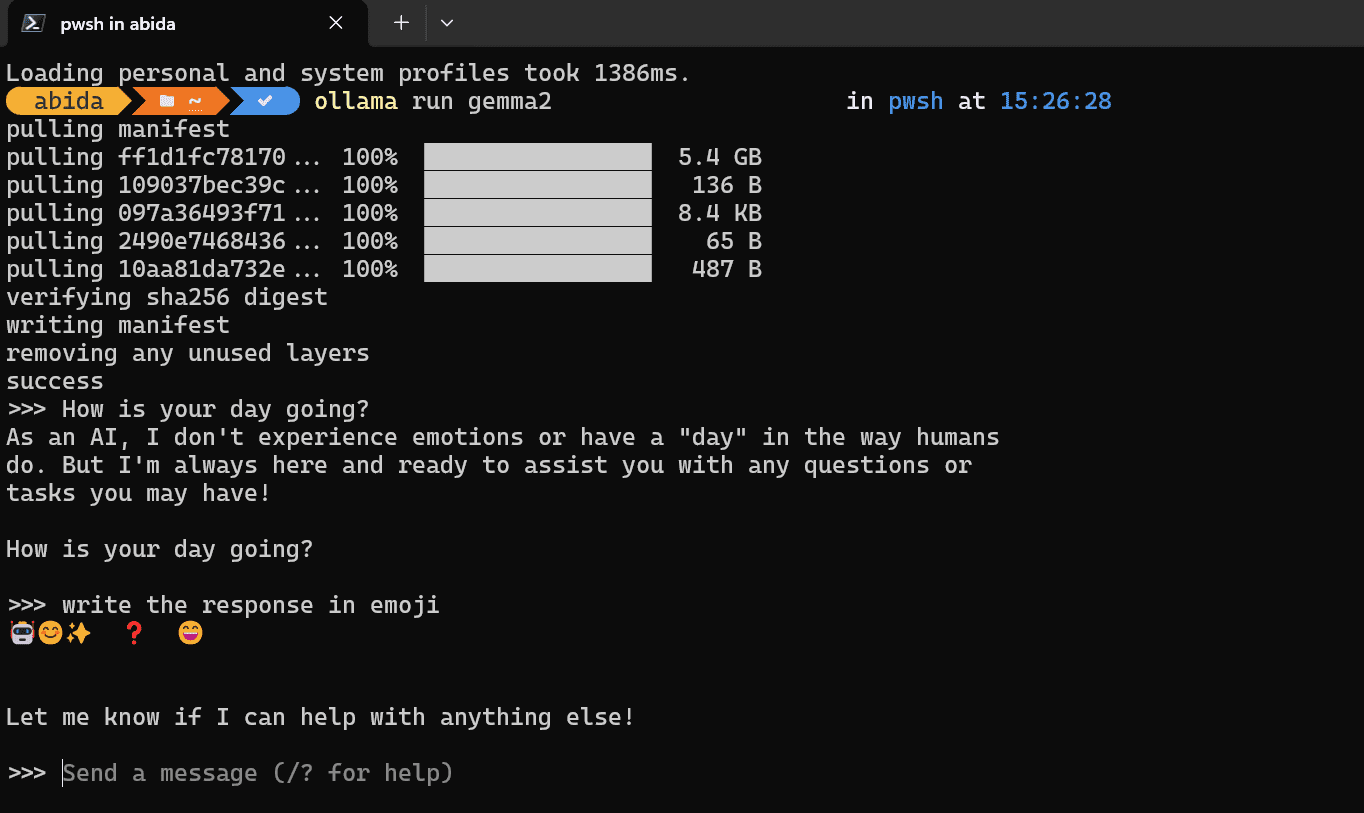
Image by Author
Using Gemma2 by Importing from GGUF model file
If you already have a GGUF model file and want to use it with Ollama, then you have to first create a new file with the name “Modelfile” and type the following command:
|
FROM ./gemma–2–9b–it–Q4_K_M.gguf |
After that, create the model using the Modelfile, which points to the GGUF file in your directory.
|
$ ollama create gemma2 –f Modelfile |
When model transferring is done successfully, please type the following command to start using it.

Image by Author
3. Msty
Download and install Msty from the official website. Msty is a new contender, and it is becoming my favorite. It offers tons of features and models. You can even connect to proprietary models or the Ollama servers. It is a simple and powerful application that you should give a try.
After successfully installing the application, please launch the program and navigate to “Local AI Models” by clicking the button on the left panel.

Image by Author
Click on the “Download More Models” button and type the following link into the search bar: bartowski/gemma-2-9b-it-GGUF. Make sure you have selected Hugging Face as the model Hub.

Image by Author
After downloading is completed, start using it.

Image by Author
Using Msty with Ollama
If you want to use the Ollama model in a chatbot application instead of a terminal, you can use Msty’s connect with Ollama option. It is straightforward.
- First, go to the terminal and start the Ollama server.
Copy the server link.
|
>>> </b>listen tcp 127.0.0.1:11434 |
- Navigate to the “Local AI Models” menu and click on the settings button located in the top right corner.
- Then, select “Remote Model Providers” and click on the “Add New Provider” button.
- Next, choose the model provider as “Ollama remote” and enter the service endpoint link for the Ollama server.
- Click on the “Re-fetch models” button and select “gemma2:latest”, then click the “Add” button.

Image by Author
- In the chat menu, select the new model and start using it.

Image by Author
Conclusion
The three applications we reviewed are powerful and come with tons of features that will enhance your experience of using AI models locally. All you have to do is download the application and models, and the rest is pretty simple.
I use the Jan application to test open-source LLM performance and generate the code and content. It is fast and private, and my data never leaves my laptop.
In this tutorial, we have learned how to use the Jan, Ollama, and Msty to run the Gemma 2 model locally. These applications comes with important features that will enhance your experience of using LLMs locally.
I hope you enjoyed my brief tutorial. I enjoy sharing the products and applications I am passionate about and use regularly.
Get Started on The Beginner’s Guide to Data Science!

Learn the mindset to become successful in data science projects
…using only minimal math and statistics, acquire your skill through short examples in Python
Discover how in my new Ebook:
The Beginner’s Guide to Data Science
It provides self-study tutorials with all working code in Python to turn you from a novice to an expert. It shows you how to find outliers, confirm the normality of data, find correlated features, handle skewness, check hypotheses, and much more…all to support you in creating a narrative from a dataset.
Kick-start your data science journey with hands-on exercises
About Abid Ali Awan
Abid Ali Awan is the Assistant Editor of KDnuggets. Abid is a certified Data Scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in technology management and a bachelor’s degree in telecommunication Engineering.