

Understanding RAG Part X: RAG Pipelines in Production
Image by Editor | Midjourney & Canvas
Be sure to check out the previous articles in this series:
Pipelines play a central role in deploying software, as they facilitate the automation and orchestration of several tasks in production environments, guaranteeing smooth data and process flows. In the context of advanced systems, like retrieval augmented generation (RAG) applications, pipelines in production attain even more significance. They are crucial in maintaining reasonable levels of efficiency, scalability, consistency among components, and reliability while managing complex workflows.
This part of the Understanding RAG series focuses on discussing the key characteristics of RAG pipelines in production, distinguishing between three types of pipelines: the indexing pipeline, the retrieval pipeline, and the generation pipeline. Each type of pipeline has its role in the overall RAG architecture, and understanding how they interact is vital for optimizing performance and having the system produce timely, relevant, and factually correct results.
Along the below description of the three RAG pipelines, we will be exploring the elements shown in this visual diagram:
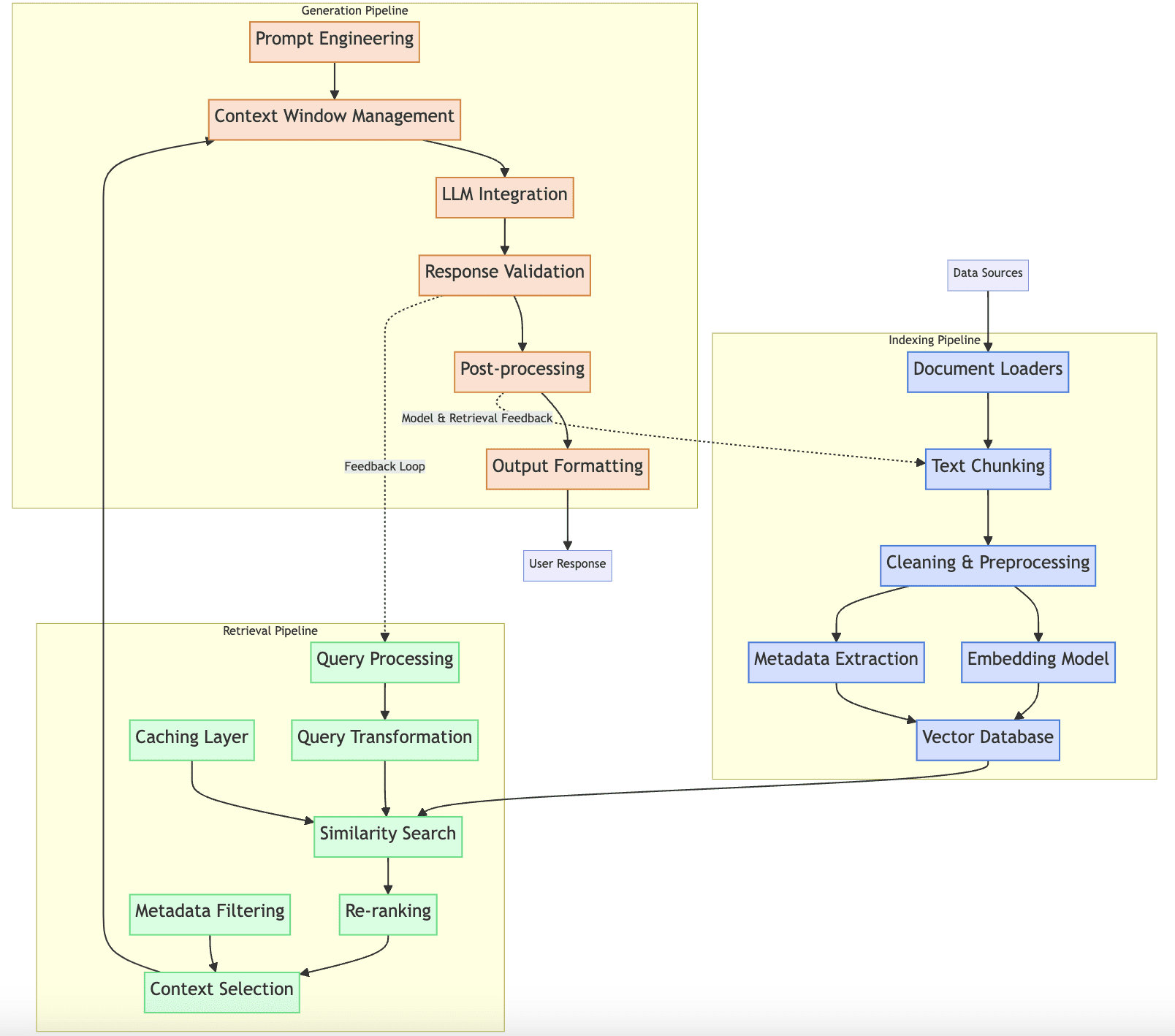
RAG production pipelines
Indexing Pipeline
The purpose of the indexing pipeline in an RAG system is to collect, process, and store documents in a vector database for efficient retrieval. Simply put, the indexing pipeline looks after the RAG system’s document database.
To do this, it relies on the following components:
- Document loaders that collect and load documents for multiple sources in different formats like PDF, web pages, and so on.
- Text chunking strategies to ensure long documents are integrated into the vector database in manageable portions. These strategies include overlap settings to keep the semantic relationship between chunks from the same document.
- Data pre-processing workflows, that apply steps like cleaning, filtering, and removing duplicates in document-related data.
- Embedding models that will convert the text to numerical vector representations or embeddings.
- The vector database where documents will be stored for future retrieval
- Methods for document metadata extraction.
These components are orderly represented inside the “indexing pipeline” block in the diagram shown earlier. How does an indexing pipeline interact with the other pipelines in the RAG system? As you may guess, this pipeline provides processed and stored documents to the retrieval pipeline, after having applied some similarity-based search for instance. The processes taking place along the pipeline must be designed in an aligned and coherent fashion with the retrieval strategy: for instance, the chunking method and settings normally impact retrieval quality. A good maintenance strategy for the indexing pipeline must support incremental updates to have fresh data available anytime.
Retrieval Pipeline
The retrieval pipeline is responsible for finding and extracting the most relevant context from the vector database every time a query is submitted by a user. It directly communicates with the other two RAG pipelines — indexing pipeline and generation pipeline — and its components are:
- Query understanding and preprocessing: before processing the query, a simpler language model focused on language understanding tasks like intent recognition or named entity recognition (NER) could be used for a better understanding of the original query before preprocessing it.
- Query transformation mechanisms like query expansion, decomposition, etc.
- The similarity search algorithm is a key part of the RAG system’s retriever and this pipeline. By interacting with the vector database through orchestration with the indexing pipeline, similarity metrics like cosine or Euclidean distance are used to find the most relevant stored documents to the processed query. A caching layer can be used here to efficiently manage frequent queries.
- If we implement a re-ranking strategy, the re-ranking mechanism becomes also part of this pipeline.
- Context filtering or selection based on metadata, to select the most relevant information among the retrieved documents.
This pipeline can be further enhanced by incorporating hybrid search capabilities, like semantic and keyword-based search.
In terms of interactions, the retrieval pipeline consumes data from the indexing pipeline and sends the retrieved context it builds to the generation pipeline that governs the RAG system’s language model. It can also provide feedback to the indexing pipeline for optimizing its operation.
Generation Pipeline
This pipeline has the goal of creating coherent, accurate responses utilizing the language model and the retrieved context built by the retrieval pipeline. Its key components or stages are:
- Prompt engineering and templating to prepare the context as the language model’s input.
- Context window management is necessary in cases like handling long context to ensure relevant information fits within the language model’s limitations like input token length.
- LLM selection and configuration are crucial in real-world RAG applications that usually have several models fine-tuned for specialized tasks like summarization, translation, or sentiment analysis.
- Response validation procedures to validate and post-process the raw generated output.
- Response formatting and structuring for its presentation to the end user.
The generation pipeline receives the relevant context from the retrieval pipeline and serves as the final phase that delivers responses to users. It can include feedback loops based on interaction with the other components for fostering continuous improvement.
Wrapping Up
This article of the RAG series discussed the three main types of pipelines an RAG system normally integrates once deployed in production environments. For optimal RAG application performance and guaranteed success, it is important that each pipeline is monitored, versioned, and enhanced independently while ensuring they operate together seamlessly.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.