

LLM Evaluation Metrics Made Easy
Image by Author | Ideogram
Metrics are a cornerstone element in evaluating any AI system, and in the case of large language models (LLMs), this is no exception. This article demystifies how some popular metrics for evaluating language tasks performed by LLMs work from inside, supported by Python code examples that illustrate how to leverage them with Hugging Face libraries easily.
While the article focuses on understanding LLM metrics from a practical viewpoint, we recommend you check out also this supplementary reading that conceptually examines elements, guidelines, and best practices for LLM evaluation.
Pre-requisite code for installing and importing necessary libraries:
|
!pip install evaluate rouge_score transformers torch import evaluate import numpy as np |
Evaluation Metrics From Inside
The evaluation metrics we will explore are summarized in this visual diagram, along with some language tasks where they are typically utilized.
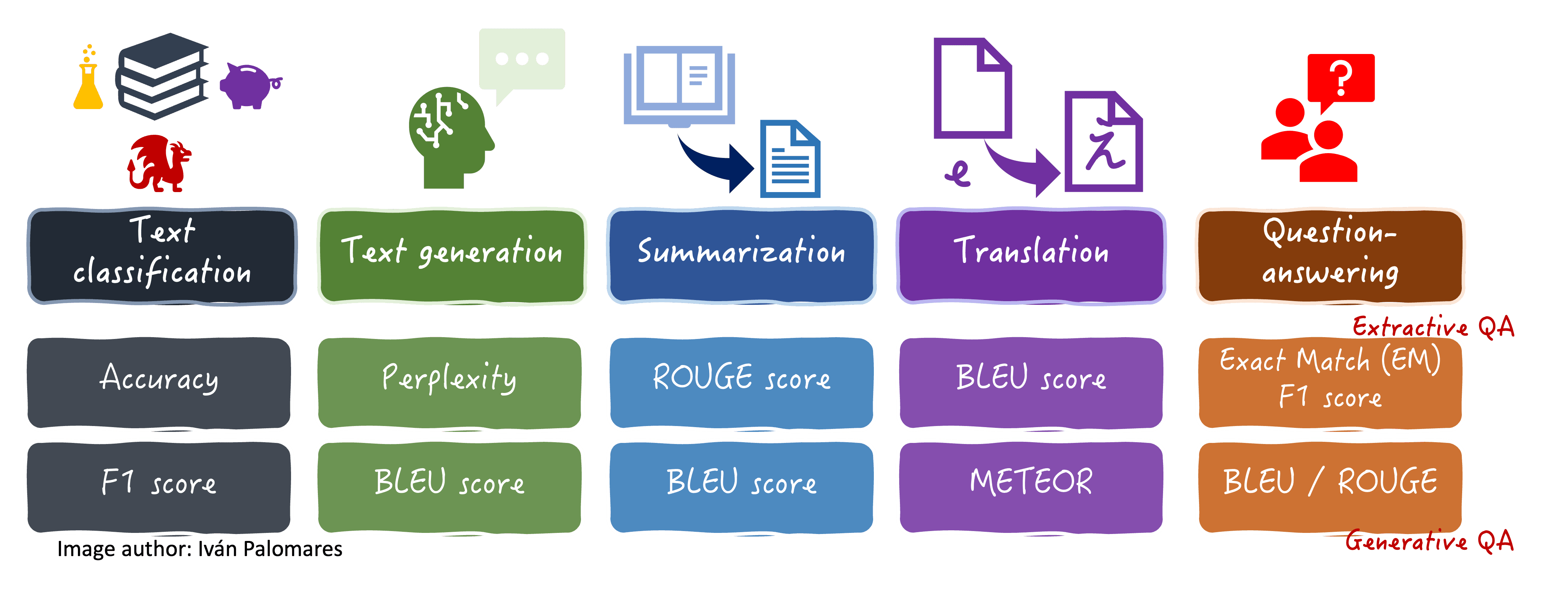
Evaluation metrics for different language tasks
Accuracy and F1 Score
Accuracy measures the overall correctness of predictions (normally classifications) by computing the percentage of correct predictions out of total predictions. The F1 score provides a more nuanced approach, especially for evaluating categorical predictions in the face of imbalanced datasets, combining precision and recall. Within the LLM landscape, they are used both in text classification tasks like sentiment analysis, and other non-generative tasks like extracting answers or summaries from input texts.
Suppose you’re analyzing sentiment in Japanese anime reviews. While accuracy would describe the overall percentage of correct classifications, F1 would be particularly useful if most reviews were generally positive (or, on the contrary, mostly negative), thus capturing more of how the model performs across both classes. It also helps reveal any bias in the predictions.
This example code shows both metrics in action, using Hugging Face libraries, pre-trained LLMs, and the aforesaid metrics to evaluate the classification of several texts into related vs non-related to the Japanese Tea Ceremony or 茶の湯 (Cha no Yu). For now, no actual LLM is loaded and we suppose we already have its classification outputs in a list called pred_labels. Try it out in a Python notebook!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Sample dataset about Japanese tea ceremony references = [ “The Japanese tea ceremony is a profound cultural practice emphasizing harmony and respect.”, “Matcha is carefully prepared using traditional methods in a tea ceremony.”, “The tea master meticulously follows precise steps during the ritual.” ]
predictions = [ “Japanese tea ceremony is a cultural practice of harmony and respect.”, “Matcha is prepared using traditional methods in tea ceremonies.”, “The tea master follows precise steps during the ritual.” ]
# Accuracy and F1 Score accuracy_metric = evaluate.load(“accuracy”) f1_metric = evaluate.load(“f1”)
# Simulate binary classification (e.g., ceremony vs. non-ceremony) labels = [1, 1, 1] # All are about tea ceremony pred_labels = [1, 1, 1] # Model predicts all correctly
accuracy = accuracy_metric.compute(predictions=pred_labels, references=labels) f1 = f1_metric.compute(predictions=pred_labels, references=labels, average=‘weighted’)
print(“Accuracy:”, accuracy) print(“F1 Score:”, f1) |
Feel free to play with the binary values in the labels and pred_labels lists above to see how this affects the metrics computation. The below code excerpts will consider the same example text data.
Perplexity
Perplexity measures how well an LLM predicts a sample-generated text by looking at each generated word’s probability of being the chosen one as next in the sequence. In other words, this metric quantifies the model’s uncertainty. Lower perplexity indicates better performance, i.e. the model did a better job at predicting the next word in the sequence. For instance, in a sentence about preparing matcha tea, a low perplexity would mean the model can consistently predict appropriate subsequent words with minimal surprise, like ‘green’ followed by ‘tea’, followed by ‘powder’, and so on.
Here’s the follow-up code showing how to use perplexity:
|
# Perplexity (using a small GPT2 language model) perplexity_metric = evaluate.load(“perplexity”, module_type=“metric”) perplexity = perplexity_metric.compute( predictions=predictions, model_id=‘gpt2’ # Using a small pre-trained model ) print(“Perplexity:”, perplexity) |
ROUGE, BLEU and METEOR
BLEU, ROUGE, and METEOR are particularly used in translation and summarization tasks where both language understanding and language generation efforts are equally needed: they assess the similarity between generated and reference texts (e.g. provided by human annotators). BLEU focuses on precision by counting matching n-grams, being mostly used to evaluate translations, while ROUGE measures recall by examining overlapping language units, often used to evaluate summaries. METEOR adds sophistication by considering additional aspects like synonyms, word stems, and more.
For translating a haiku (Japanese poem) about cherry blossoms or summarizing large Chinese novels like Journey to the West, these metrics would help quantify how closely the LLM-generated text captures the original’s meaning, words chosen, and linguistic nuances.
Example code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# ROUGE Score (no LLM loaded, using pre-defined lists of texts as LLM outputs (predictions) and references) rouge_metric = evaluate.load(‘rouge’) rouge_results = rouge_metric.compute( predictions=predictions, references=references ) print(“ROUGE Scores:”, rouge_results)
# BLEU Score (no LLM loaded, using pre-defined lists of texts as LLM outputs (predictions) and references) bleu_metric = evaluate.load(“bleu”) bleu_results = bleu_metric.compute( predictions=predictions, references=references ) print(“BLEU Score:”, bleu_results)
# METEOR (requires references to be a list of lists) meteor_metric = evaluate.load(“meteor”) meteor_results = meteor_metric.compute( predictions=predictions, references=[[ref] for ref in references] ) print(“METEOR Score:”, meteor_results) |
Exact Match
A pretty straightforward, yet drastic-behaving metric, exact match (EM) is used in extractive question-answering use cases to check whether a model’s generated answer completely matches a “gold standard” reference answer. It is often used in conjunction with the F1 score to evaluate these tasks.
In a QA context about East Asian history, an EM score would only count as 1 (match) if the LLM’s entire response precisely matches the reference answer. For example, if asked “Who was the first Shogun of the Tokugawa Shogunate?“, only a word-for-word match with “Tokugawa Ieyasu” would yield an EM of 1, being 0 otherwise.
Code (again, simplified by assuming the LLM outputs are already collected in a list):
|
# 6. Exact Match def exact_match_compute(predictions, references): return sum(pred.strip() == ref.strip() for pred, ref in zip(predictions, references)) / len(predictions)
em_score = exact_match_compute(predictions, references) print(“Exact Match Score:”, em_score) |
Wrapping Up
This article aimed at simplifying the practical understanding of evaluation metrics usually utilized for assessing LLMs’ performance in a variety of language use cases. By combining example-driven explanations with illustrative code-based examples of their use through Hugging Face libraries, we hope you gained a better understanding of these intriguing metrics not commonly seen in the evaluation of other AI and machine learning models.